Project Details
Deep Learning : Vocal language recognition with CNN

In the field of vocal recognition, speech recognition, or known as speach2text, for commonly used languages is very popular.
Speech recognition is an interdisciplinary subfield of computer science and computational linguistics that develops methodologies and technologies that enable the recognition and translation of spoken language into text by computers.
But there are few vocal recognition models for rare languages. So, here is a new project from another perspective: detecting rare languages from vocal audio files.

The audio source data comes from open-source vocal recording websites, and we have chosen 4 languages with some linguistic similarities: Chinese, Mongolian, Tatar, and Estonian.
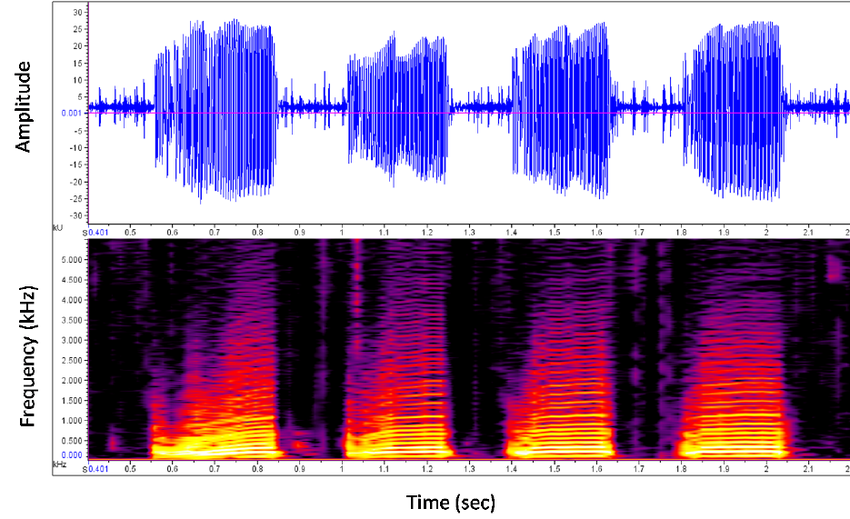
There are many methods to convert audio files into computers understandable data. In this project, we have chosen to transform audio files into spectrograms and using image recognition features to solve the problem.
The reason is that different languages can be more easily distinguished with their vowel pronunciations, whereas consonants in different languages have few remarkable differences. And different vowel pronunciations represented on spectrograms can be quite useful to develop this language detection model.
Then, we used OpenCV and Keras to build a model based on these spectrograms.

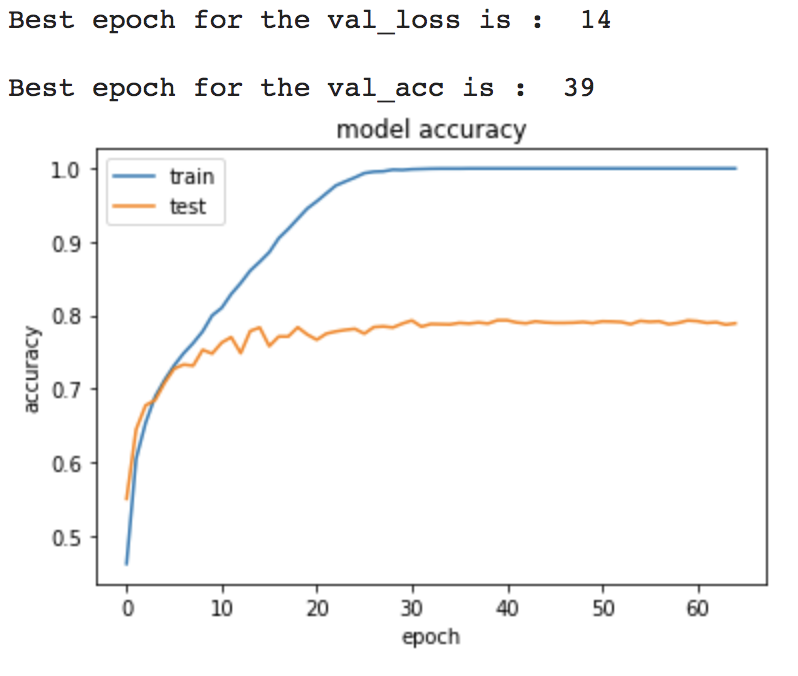
After the first model fitting and hyper-parameter tuning, we obtained an accuracy of 0.79, not bad, but still with many possibilities of improvements.
The result shows an overfitting problem that can be solved in 3 directions :
- Reduce overfitting by training the network on more examples
- Reduce overfitting by changing the complexity of the network
- Reduce overfitting by different regularization methods
This will be the major future work to be done. Then, in the next level, we can maybe test this model framework with other languages to see whether there is a possibility of algorithm generalization.