Project Details
A multilingual NLP toolkit interface

This is a project in python creating a program with a user interface to detect language, proceed with tokenization and POS tagging, and show statistic information of the input corpus.
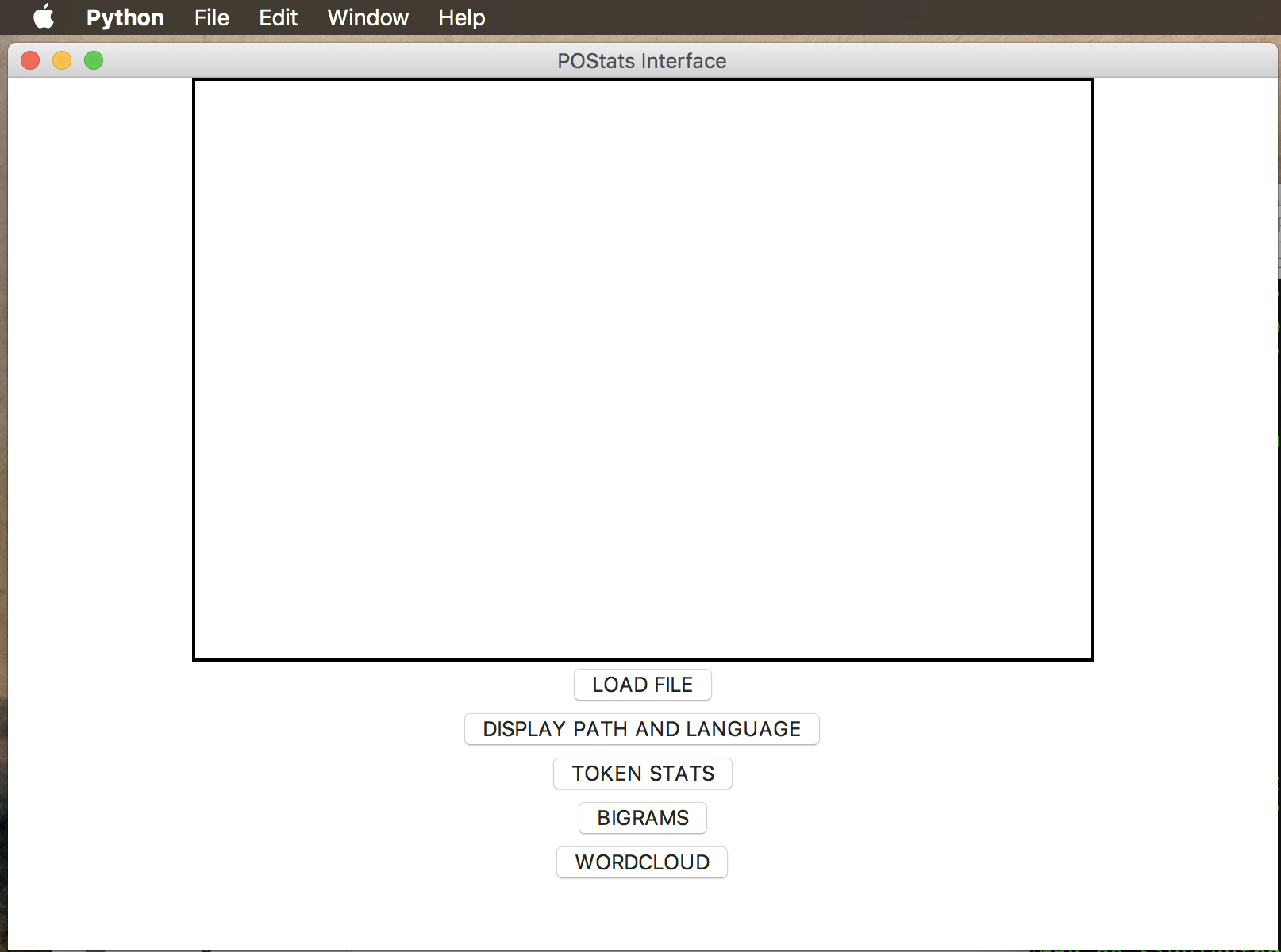
With this interface, you can upload a text file of any language and proceed with the tokenization, POS tagging, and statistic analysis.
If no file loaded, an error message will occur.
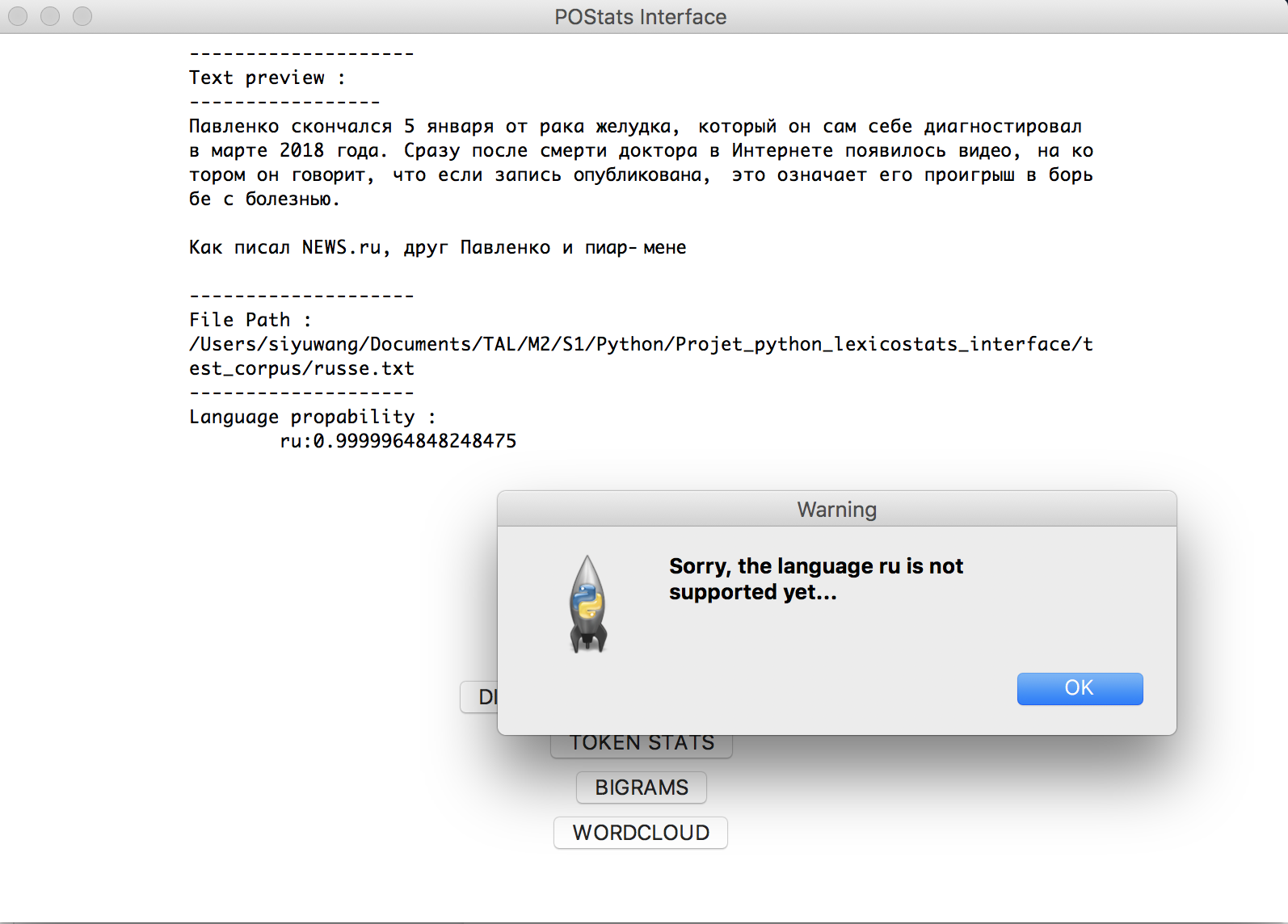
The supporting languages are :
- English
- French
- Chinese
- Italian
- German
- Spanish
This toolkit will detect the language of the input text file, and if the file is written in a non-supported language, an error message will occur.
With our interface, you can generate a word cloud based on your txt file and the word occurrence.
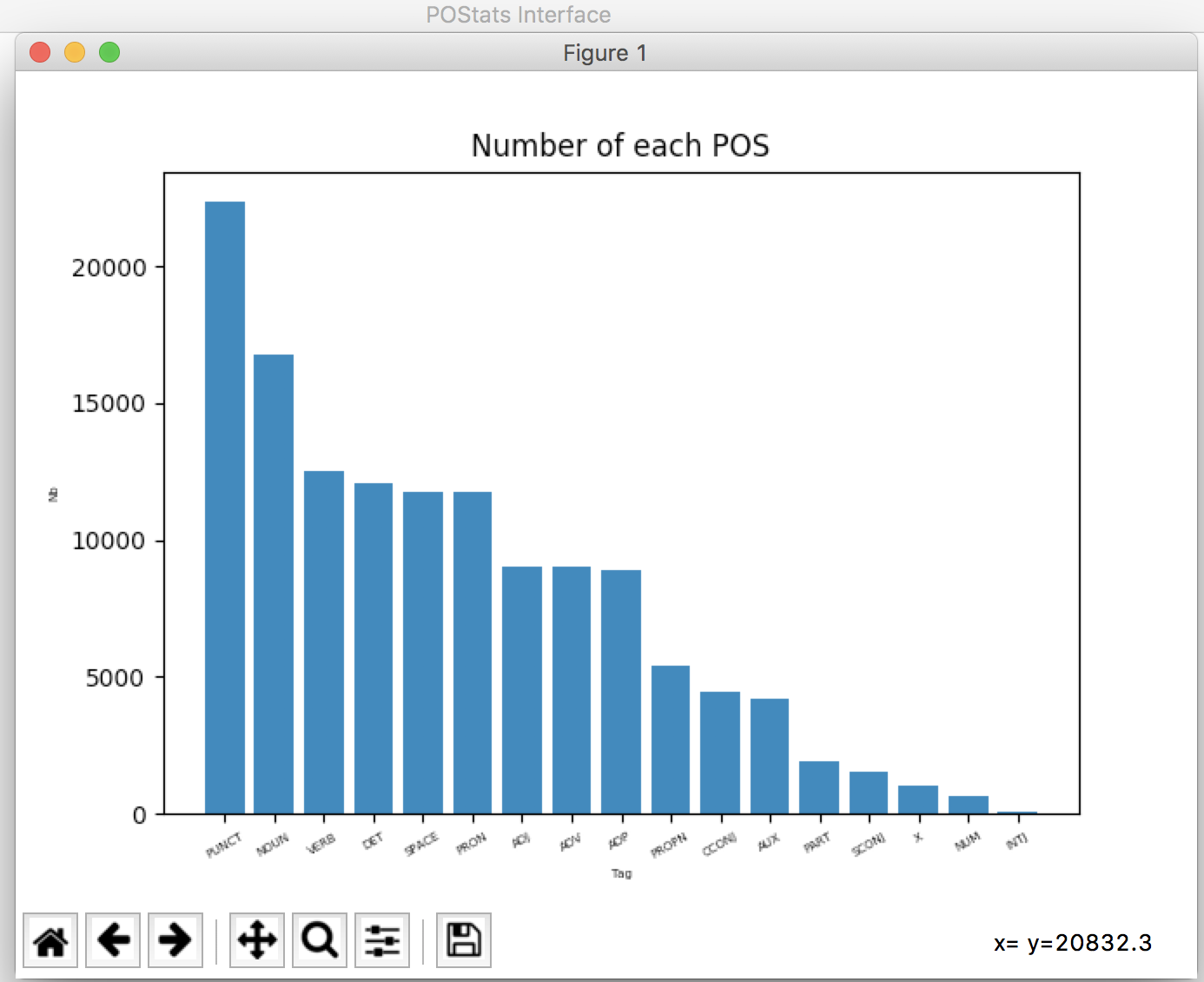
You can also check other statistical information such as the percentage of each POS, the most popular word, the most popular bigrams, etc...